


我本科学习了生物统计学,但学习得并不扎实,存在很多盲区和死角,前段时间重新学习了一遍,收获颇丰,第一个体会就是,其实对于统计,大多数人包括我连最基本的概念都没有理解透彻,这一篇我将我对基本概念的理解跟大家交流。
01
总体和样本
总体:是根据研究目的确定的,所有同质研究对象某一(组)指标值的集合。总体分为有限总体和无限总体。在没有时间、空间限定情况下,同质研究对象个体数无限者为无限总体。
样本:是从总体中随机抽取的、数量足够的、能代表总体特征的部分研究对象某一(组)指标值的集合,我们都知道,样本要具备代表性和可靠性,才能准确反映总体的真实情况,因此抽样时要随机,并且保证足够的样本量。在做统计分析或者利用统计学设计方案时,要分清楚总体和样本的区别。通常通过样本的观测值来推断总体的情况。因此对于总体而言,其参数的可信度依赖于样本,我之所以反复提这个概念,是因为无限总体的客观上永远都是虚拟的理想的,样本只能尽可能准确地去反映总体。
02
参数和统计量
以上内容可能接触统计的人都理解,统计学的一大任务就是从样本推断总体。统计学把描述总体特征的指标称为参数,描述样本特征的指标称为统计量。由样本信息(即样本统计量)推断总体特征(即总体参数)的过程称为统计推断。举个例子来说,对于正态分布,一般用均值和标准差来表示,比如
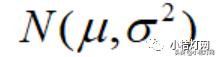
,表示的是均值μ,标准差为σ的正态分布,那么描述总体特征的参数为均值μ,标准差σ。为了推断这两个参数,我们抽取一个样本,通过计算,得出样本的均值为
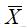
,标准差为S,可以通过
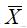
、S来推断μ、σ,因此把
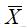
、S叫做统计量。因此关于统计量,也可以理解为从样本数据得来的用于推断总体参数的量,它既可以反映样本特征,又可以估计总体参数。
03
标准差和标准误
标准差:我们都知道标准差和方差都是基于离均差的描述所有观测值的变异指标。怎么理解这句话呢?离均差平方和(sum of squares of deviations from mean,SS)=
![]()
![]()
(X是观测的实际值,μ是总体均数)其反映了全部观察值的变异程度,其值越大,个体观测值之间的变异程度越大。方差
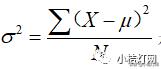
是在离均差平方和的基础上消除了例数N的影响,其反映了每个观察值的平均变异。总体方差用
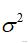
表示,样本方差用
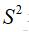
表示。
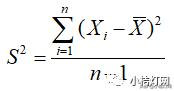
(这里需要说明一下,通常总体例数用N表示,样本例数用n表示。总体均数用μ表示,样本均数用
表示。)
可以看到样本方差公式里的分母是n-1,这个通常称为自由度。自由度在统计学中指的是计算某一统计量时,取值不受限制的变量个数。关于对自由度的理解,我在后面的文章中会专门介绍。那么问题来了,我们已经有了方差来描述观测值之间的变异程度,为什么还要将其开方,引入标准差来描述变异呢?可以看到,方差的单位是原始单位的平方,在实际应用中会出现一些问题,比如
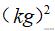
就没有实际意义,因此,将方差开平方获得和原始数据一样的统计指标更加合理。标准差是方差的平方根,具有和原始数据一样的单位,不存在解释上的困难。
标准误:通常将样本统计量的标准差称为标准误(standard error,SE)。怎么来理解标准误的定义,以及统计中用标准误衡量什么呢?又要提到,通过样本来推断总体,因此对抽样有着最基本的要求,即前面提到过的保证足够的样本量并遵循随机化的原则。但是由于个体差异的存在,通过所抽取的样本推断总体时会存在一定的误差。举个例子来说,从正态分布总体中
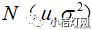
中随机抽取10人(n=10)为一个样本,并计算该样本的均数和标准差,如此重复抽取100次(g=100),可得到100份样本,同时也可以得到100对均数
和标准差S;将这100份样本的均数看成新的变量值,再计算其均值和标准差,称之为均数的均数和均数的标准差。我们应该能够想到,由于抽样误差的存在,各样本均数间存在差异,各样本均数与总体均数未必相等。同样的,由于样本量的存在,各样本均数之间的差异要小于原个体变量间的变异。我们把样本均数之间的这种变异,叫做均数标准误(SEM),即统计量为均数的标准差,它反映样本均数间的离散程度,也反映样本均数与总体均数间的差异,因而说明了均数抽样误差的大小。理论上可证明均数的标准误为
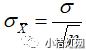
;但在实际工作中,由于总体标准差σ往往是未知的,需要用样本标准差S来估计。因此均数标准误的估计值
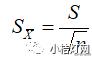
。那么,关于标准差和标准误的区别,我想大家看到这里,应该能理解了,标准差描述观测值之间的平均变异,标准误描述样本均数之间的变异,标准误反映抽样误差的大小,我们从上面的公式可以看到,标准误的大小与标准差成正比,和样本含量n的平方根成反比,若标准差固定不变,可以通过增加样本含量n来减少均数的标准误,从而降低抽样误差。
04
参数估计和假设检验
参数估计:参数估计是指用样本统计量估计总体参数的大小,分为点估计和区间估计。点估计就是点对点的估计,用样本的一个统计量去估计总体的一个参数,如用样本均数
估计总体均数μ等。但是点估计并没有考虑抽样误差的大小,因此虽简单,但很难估计准确。为此,我们需要区间估计,区间估计是按照预先给定的概率(1-α)估计总体参数所在的范围,该范围被称为总体参数的可信区间或置信区间。
假设检验:首先,我们先思考下,假设检验的目的是什么?个人觉得如果这个问题可以回答清楚,其实后面的文字不用看了。我们都知道,在抽样研究中,抽样误差是不可避免的,比如,我们从一个总体中抽取两个样本,两个样本的均数很可能不一样。那么,在实际工作中,我们遇到如样本统计量(如样本均数
)与某总体参数(如已知总体均数
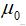
)不等,或者两个样本统计量(如样本均数
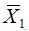
和
![]()
![]()
)不等时,这种不相等反映了两种情况,第一种,这种不相等仅仅是由抽样误差造成的,不存在本质上的不同,因为样本是随机抽取的。第二种,样本来自于不同的总体,存在本质的不同。那么,为了判断均数间的差异是由抽样误差造成的还是存在本质上的差异,需要通过假设检验来回答。假设检验也称为显著性检验。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
 微信扫一扫
微信扫一扫