
【摘要】 近年来,华为云边缘云创新lab与多个知名校企研究团队密切合作并持续开展技术研究,希望以楼宇智能为依托逐步解决边缘智能问题。
近年来,随着边缘计算技术的崛起,边缘智能相关的场景应用拓展也成为科技公司争相展现技术创新和商业价值的路径,各种边缘AI的解决方案亦应运而生,如华为云智能边缘平台IEF,一站式端云协同多模态AI开发平台HiLens。据统计,现代城市人的生活与工作同楼宇息息相关,超过80%的时间都是在城市楼宇中度过,楼宇智能毋庸置疑是影响深远的关键研究课题。本文将围绕楼宇智能其中最重要的课题之一中央空调能效预测与管理来展开,目前,该课题面临最大的瓶颈是:现有的大多数能效预测与管理方法仅限于云端单任务,无法支撑中央空调能效模型在边缘隐含的大量复杂场景上的能力。
众所周知,暖通空调系统(包括供暖,通风和空调)主导着商业建筑的用电量。对暖通空调系统的现有研究表明,准确量化冷水机组的能效比(数值越大越节能)非常重要,近期提出的数据驱动的能效比预测可以被应用到云上。但是,由于不同园区拥有不同型号的空调或不同种类的传感器,导致不同边缘各个项目在特征、模型等方面区别很大,在小样本情况下很难用一个通用模型适应所有的项目。
Zheng, Z., Wang Y., Dai Q., Zheng H., Wang, D. "Metadata-driven task relation discovery for multi-task learning." In Proceedings of IJCAI (CCF-A), 2019.
在这篇论文中有一个多任务的实际应用案例,不同边缘智能项目采用不同设备使得边缘侧模型不同,从而可以应用于多任务设定。这篇论文的亮点是引入元数据,元数据是数据集的描述信息,在复杂系统中用于日常系统运作,蕴含专家信息。基于元数据提取任务属性,本论文设计了元数据任务属性与样本任务属性层次结合的多任务通用AI算法(图1)。相关论文专家评审也认为该技术在应用实践中显示了实用价值,对机器学习项目真正落地具备重要意义,将成为当今大型组织感兴趣的技术。
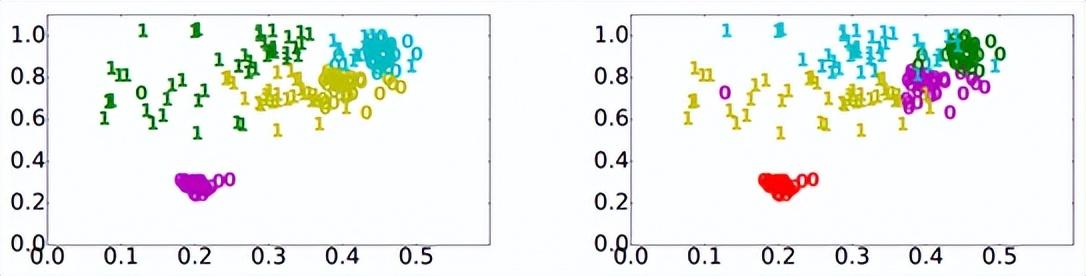

图1 颜色代表不同聚类簇,数字代表不同设备型号。基于样本属性的方法容易导致负迁移(同一簇中混淆不同型号设备模型,左图),而基于元数据的方法可以避免负迁移(右图)。
Zheng, Z., Chen, Q., Hu, C., Wang, D., & Liu, F. "On-edge Multi-task Transfer Learning: Model and Practice with Data-driven Task Allocation." In Proceedings of IEEE TPDS (CCF-A), 2019.
Chen, Q., Zheng, Z., Hu, C., Wang, D., & Liu, F. "Data-driven task allocation for multi-task transfer learning on the edge. " In Proceedings of IEEE ICDCS (CCF-B), 2019.
多任务迁移学习是解决边缘上样本不足的典型做法。而目前边缘上的任务分配调度工作通常假设不同的多个任务是同等重要的,导致资源分配在任务层面不够高效。为了提升系统性能与服务质量,我们发现不同任务对决策的重要性是一个亟需衡量的重要指标。我们证明了基于重要性的任务分配是NP-complete的背包问题变种,并且在多变的边缘场景下该复杂问题的解需要被频繁地重新计算。因此我们提出一个用于解决该边缘计算问题的AI驱动算法,并且在实际多变的边缘场景中进行算法测试(图2),与SOTA算法相比该算法能减少3倍以上的处理时间和近50%的能源消耗。
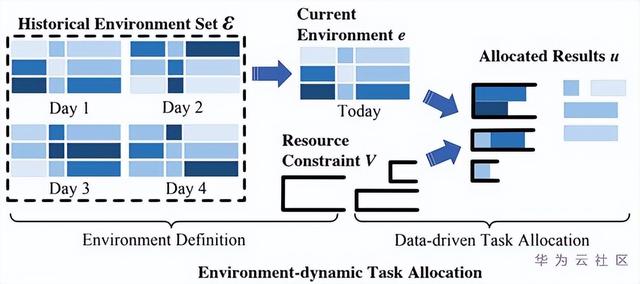
图2 根据边缘场景动态进行任务分配调度
Zheng, Z., Chen, Q., Fan, C., Guan, N., Vishwanath, A., Wang, D., & Liu, F. "Data Driven Chiller Sequencing for Reducing HVAC Electricity Consumption in Commercial Buildings." In Proceedings of ACM e-Energy, 2018. Best Paper Award.
Zheng, Z., Chen, Q., Fan, C., Guan, N., Vishwanath, A., Wang, D., & Liu, F. "An Edge Based Data-Driven Chiller Sequencing Framework for HVAC Electricity Consumption Reduction in Commercial Buildings." IEEE Transactions on Sustainable Computing, 2019.
多任务可以应用于楼宇节能中。冷机是楼宇中的耗能大户。冷机能效预测与管理,预测冷机负荷决策的能效比并优化冷机负荷决策,一直是楼宇智能最重要的研究问题之一。本研究观测到,在冷机决策能效预测中,不同边缘项目的设备型号和工况不同会导致最终需求的模型不同。这种情况下仅采用云端单一模型的做法容易导致精度下降和决策失误。本工作研发了一种边云协同的多任务冷机负荷决策框架(图3),在利用现有端边节点且不部署额外硬件的情况下,较当前工业界方法节能30%以上。
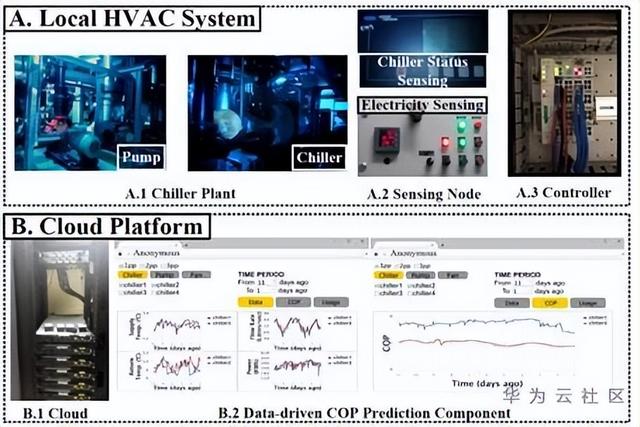
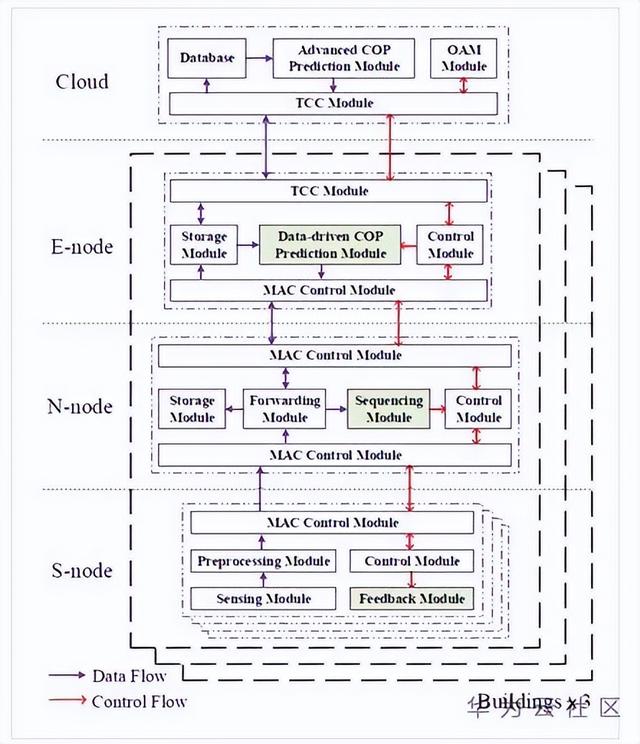
图3 边云协同的冷机负荷决策框架
Zheng, Z., Dai Y., Wang D., "DUET: Towards a Portable Thermal Comfort Model." In Proceedings of ACM BuildSys (Core rank A), 2019.
Yang, L., Zheng, Z., Sun, J., Wang, D., & Li, X. A domain-assisted data driven model for thermal comfort prediction in buildings. In Proceedings of ACM e-Energy. 2018.
空调舒适度预测是楼宇智能历史长河中重要的研究课题之一。目前的舒适度预估方法通常要求额外的传感器或者用户反馈等人工干预,这使得规模化本身成为难题。基于机器学习方法的空调舒适度预测已被证明可以减少额外的人工干预。但在不同边缘场景下,楼宇制冷类型、安装传感器类别等因素会使得云上单一通用模型出现严重错误。本研究提出了一种多任务的方法进行空调舒适度的预测,在精度上较机理模型和单任务模型分别提升39%和31%。
基于以上项目,读者可以了解到基于多任务的边缘智能算法、系统与应用。值得注意的是,在使用多任务之前,首先需要回答任务如何定义和划分的问题,如确定在一个应用内不同项目所需机器学习模型的数量以及各个模型的应用范围。该方法目前通常只能由数据科学家和领域专家人工进行干预,自动化程度低,难以规模化复制。因此,边缘自动定义机器学习任务是一个悬而未决但又重要的难题。
为了在边缘各种场景自适应地定义机器学习预测任务,华为云边缘云创新Lab近日发表了研究论文《MELODY: Adaptive Task Definition of COP Prediction with Metadata for HVAC Control and Electricity Saving》。该研究提出了一种包含任务定义的多任务预测框架(MELODY),其中任务定义能够自适应地定义并学习复数能效比预测任务。
该团队在实际应用中评估该方案的性能:基于2个大型工业园区中的8座建筑物中9台冷机进行4个月实验。实验结果表明,MELODY解决方案优于最新的能效比预测方法,并且能够为两个园区每月节省252 MWh的电量,较当前建筑中冷水机的运行方式节省了35%以上的能源。
MELODY论文已获ACM e-Energy 2020接收:
Zimu Zheng,Daqi Xie,Jie Pu,Feng Wang. MELODY: Adaptive Task Definition of COP Prediction with Metadata for HVAC Control and Electricity Saving. ACM e-Energy 2020. Australia.
ACM e-Energy 属于ACM EIG-Energy Interest Group、计算机与能源交叉的旗舰会议。
1、论文接受率23.2%,历年接受率在20%左右;
2、与CCF-A的Ubicomp; CCF-B的ECAI、TKDD H5-index相同;
3、55位评审程序委员会成员中包括Andrew A. Chien、Klara Nahrstedt、Prashant Shenoy等8位ACM/IEEE Fellow(约15%);
4、评审程序委员会成员来自IBM研究院、伊利诺伊大学香槟分校、剑桥大学、华盛顿大学、普渡大学、马萨诸塞大学阿默斯特分校、西蒙菲沙大学、南洋理工大学、清华大学、香港理工大学等国际知名校企;
5、与CCF-A的STOC、ISCA、PLDI;CCF-B的IWQos、SIG Metric、COLT、HPDC、ICS、LCTES、SPAA等同属ACM Federated Computing Research Conference (FCRC)系列的13个会议中,ACM FCRC顶会系列由Google、微软、IBM、华为、arm、Xilinx等国际知名企业赞助。
基于冷机的暖通空调系统通常用于商业建筑中,消耗的电力占建筑物总用电量的40%至70%,这种消耗量主要由暖通空调系统的消耗量决定。商业建筑物支付的电费(其中大部分归于暖通空调系统)通常位于组织运营支出的前三名。这种趋势给设施管理者带来了巨大的压力,他们需要通过减少与暖通空调系统相关的电力消耗来提高建筑的能源利用效率。
暖通空调的主要消耗来自冷机(见图4)。典型的冷机负荷控制的有效性在很大程度上取决于冷机运行时的性能,即在不同的冷负荷条件下的能效比。能效比是衡量冷机能效的指标,指的是在单位输入功率消耗下的输出冷量。能效比通常大于1,值越大,意味着效率越高。在实践中,设施管理人员通常在冷机部署到建筑物期间,在首次测试和调试冷水机组时衡量能效比的初始信息,并用该初始信息来执行冷机负荷控制。初始信息测试时通常将冷量负荷视为唯一参数。然而,这些初始信息无法捕获实际参数的影响,并且已被近期研究证明是不精确的。

图4 冷机示意图
本研究以能效比预测问题作为个例研究。能效比高度依赖于多种因素,例如工况、冷量需求、设备老化、天气等。为了在冷水机组中捕获这些因素,现有工作已经提出采用数据驱动方法。能效比预测问题可以看做是在训练阶段学习一种被称为模型的“公式”,该公式在推理阶段能够输出具有给定特征的能效比。
现有方法通常假定预测任务的配置,比如同一应用下的预测模型的数量和预测模型的应用范围,是由数据科学家或领域专家定义和固定的。下文比较三种被广泛接受的设定:单任务设定、多任务设定和专家辅助的多任务设定。
一个最典型的、被广泛接受的预测任务配置方法是基于固定的单任务设定:这意味着将所有数据集作为一个整体合并在一起,并训练单个预测模型。研究人员可以使用任何机器学习算法(例如SVM、神经网络、Boosting等)来学习这种模型,并在任何场景下的推理阶段都应用训练出的这单个模型。
单任务设定假设对于同一应用下不同项目内不同的数据集,单个模型应足以描述所选特征和能效比之间的关系。但是,这种假设可能并不总是成立。
比方说有两个园区采用了两种类型的冷水机:园区H使用了特灵CVHG1100冷水机和园区J使用了开利W3C100冷水机,那么应根据冷水机的型号调整在特征和能效比之间的热力学模型。边缘用户往往也期待看到应用到两个边缘项目的模型有所不同:即使两种冷水机输入相同的水温等特征值,输出的能效比也应不同。但如果将两个数据集合并在一起并训练同一个能效比模型,通常很难在没有人工干预的情况下确保这一点。
但目前预测任务的配置,例如所需模型的数量以及模型的应用范围,仍然是一个开放性问题。为了深入研究此问题,该团队进一步验证多任务设定而非单任务设定,也即观察多个模型在多个测试集上的性能。在一个实际建筑物中,使用了从冷机1到冷机5的训练数据集训练了5个模型(以下称为M1 – M5)。然后在另外5个测试数据集(T1 – T5)的不同场景中测试了5个模型的性能。实验及其结果分别如图5-1、5-2所示。

图5-1 复数冷机训练模型在不同冷机测试集下的实验示意图
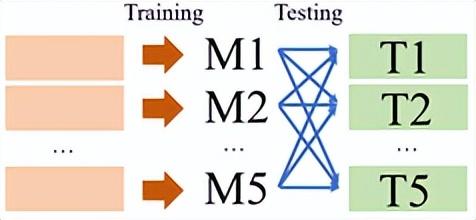
图5-1 复数冷机训练模型在不同冷机测试集下的实验示意图
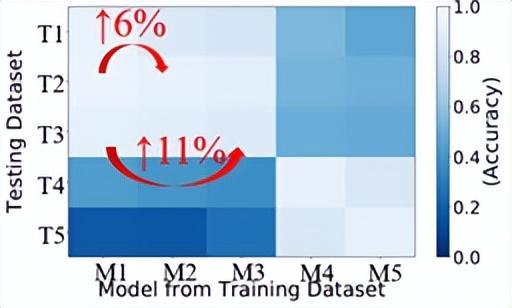
图5-2 复数冷机训练模型在不同冷机测试集下的预测准确率热力图和样本采集时间对比结果
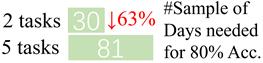
图5-2 复数冷机训练模型在不同冷机测试集下的预测准确率热力图和样本采集时间对比结果
观察结果显示,
1)精度
尽管是基于不同的数据集进行训练,但是冷机1的模型在冷机2和冷机3的测试集上效果很好,而在冷机4和冷机5的测试集上却导致严重错误。对于冷机2到冷机5的模型可以看到类似的观察结果。这是因为冷机1到冷机3来自同一种冷机型号,而冷机4和冷机5是另一种型号。
2)样本采集时间
如果按冷机来划分任务,每个冷机任务至少需要81天的样本。但如果按照型号划分为2个任务,每个型号任务仅需30天的样本。这是因为每个型号任务包含多台冷机采集的数据。
根据上述精度和样本采集时间的结果,与其考虑5个冷机从而定义5个冷机任务,在这个数据集下不如考虑2个型号(冷机1-3和冷机4-5)从而定义2个型号任务,在上述例子中可以降低约63%的样本采集时间,同时提升近10%的精度。
实际上,不仅冷机型号,随时间变化的环境(例如,天气条件)和工况(例如,供水温度)也可以导致能效比模型的变化。借助领域专家的知识,可以在构建的环境中定义固定的任务,并将这些固定的任务应用于不同的建筑中。
例如,基于建筑环境研究中的领域专业知识,该团队最近一项工作在三座建筑物中根据工况给出了固定的50个任务,用于多任务冷机能效比预测;该团队最近另外一项工作根据季节和制冷类型在160座建筑物中给出了固定的4个任务,以进行多任务热舒适性预测。
但是,所需模型的数量及其应用范围可以根据不同的边缘项目场景而变化,而领域专家的配置很难跟随不同边缘项目动态扩展。例如,在一个建筑物的少量数据集中,最好有3个任务,即训练3种不同的模型进行能效比预测。但是在另一个包含1000座建筑物的大型数据集中,最好有75个任务。在边缘场景手动定义要预测的机器学习任务通常会导致成本过高或准确性降低,尤其是当任务随项目和时间而动态变化时。因此,有必要针对不同场景自适应地定义任务。
本研究工作旨在解决自适应任务定义问题,也即不同场景下自动化定义不同的任务,例如,在不同场景中确定需要使用的模型数量以及模型的应用范围等。该团队遇到三个主要挑战,并提出了使用自适应任务定义方法的多任务预测框架(MELODY)。
挑战1:当前项目的目标未知,而且通常更糟糕的是,可能的任务候选集也未知。
MELODY通过提出任务挖掘解决了第一个挑战。它基于诸如任务森林等新颖结构和算法来自适应地定义任务,参见图6。这使得MELODY可规模化到众多建筑和环境的能效比预测。
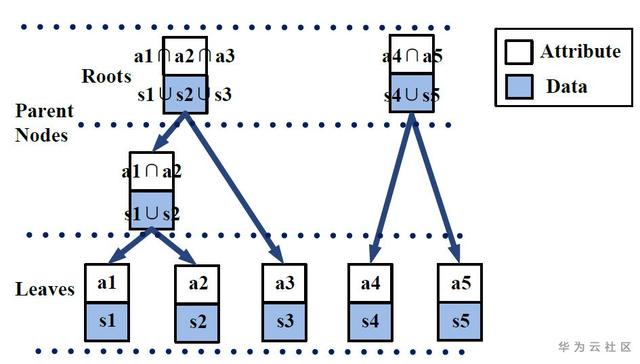
图6 任务森林的例子:数据表示模型训练样本,属性表示模型应用范围;节点表示子任务,包括数据、属性和模型(若有);森林的每个根节点,也即每棵树的顶点,表示各个子任务合并成的一个任务。对任务森林初始化和维护等具体实现和算法复杂度等证明,有兴趣的读者可以阅读论文附录。
元数据包含潜在领域信息,借助这些信息,能够自适应地提取具有领域知识的任务,并为自动和强大的任务定义打开了方便之门,如图7所示。
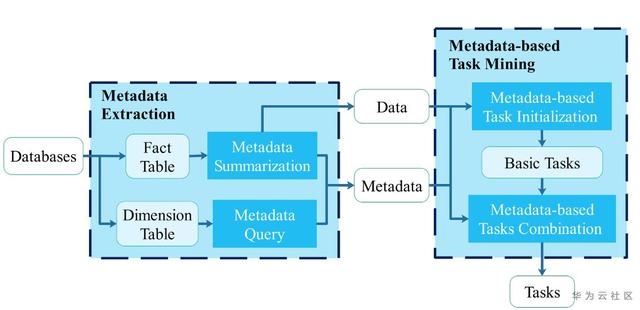
图7 基于元数据提取的任务定义(具体实现请参见论文)
挑战3:任务组合数量随属性数量指数增长;因此,冷机样本不足以为所有组合训练模型。
MELODY通过利用多任务迁移学习克服了第三个挑战。在多任务优化中,学习任务可以使用来自其他不同任务的知识,从而减少数据量的需求。
本研究工作通过将其应用于实际数据来评估方案的性能,在2个大型工业园区中的8座建筑物中9台冷机进行4个月时间的实验。园区情况可参见图8。
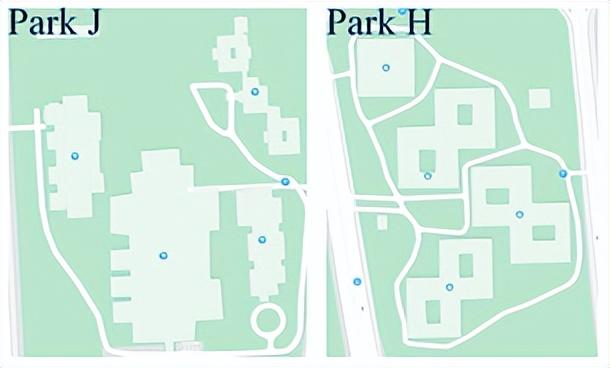
图8 2个大型工业园区中的8座建筑物及其冷机信息

图8 2个大型工业园区中的8座建筑物及其冷机信息

表1 任务定义输出结果
表1显示了通过任务定义算法挖掘出的任务的总体信息,在Park J和Park H中发现了两组不同的任务集合。观察显示不同项目模型的数量和使用模型时的场景都不同。借助五分钟的间隔数据,可以在Park J中挖掘出33个任务,这些任务模型的应用范围主要根据冷机额定功率和平均湿度的来判断。借助一小时的时间间隔数据,Park H中仅有2个任务,应用范围需要通过额定功率和额定制冷量来判断。可以发现每个任务中的样本量很小。 对于总共35个任务,有13个任务的样本数少于100,其余22个任务的样本数少于1000。
研究比较了几种应用于冷机能效预测的典型方法:
(1)工业界当前方法:初始配置文件(IP)利用安装时测量的初始配置文件来估算未来的能效比,是目前工业界正在使用的方法。
(2)学术界常用方法:单任务学习(STL)通过将来自每个数据集的所有任务的数据汇总在一起来学习一个模型;
(3)近期研究工作:关于数据源的独立多任务学习(IMTL),它独立于数据源学习每个任务。例如,针对9个冷机固定9个任务,而无需在任务之间共享任何样本或知识;
(4)近期研究工作:具有领域知识的多任务学习(MTL),它学习具有由领域知识定义的任务聚类。例如,固定的50个任务,其中10个负载比和5个冷机。
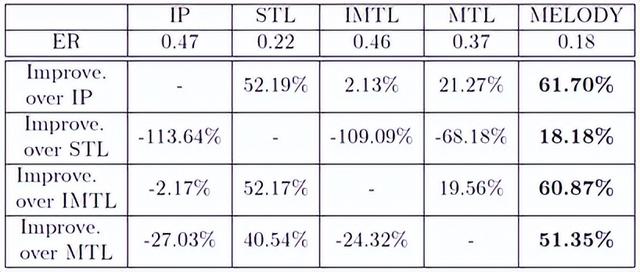
表2 各方法错误率提升
表2结果显示,MELODY的任务定义可以比STL(单任务方法)有所提升。 但是,不正确的任务定义(即IMTL和MTL)对比单任务方法未能有所提升。这主要是因为与在不同数据集中(如MELODY)使用自适应任务的方法相比,IMTL和MTL在划分任务后会生成较小的数据集,这导致部分任务内缺乏训练样本。当任务数量随着属性数目和时间推移而增加时,效果变得更差,因为任务迁移关系变得越来越复杂。在这种情况下,任务之间共享知识变得更具挑战性,并容易导致一种被称为负迁移的影响,也即从不相关的源域到目标域共享知识而导致的错误。可以看到,MELODY能解决相关问题,从而使得结果优于最新的能效比预测方法,将能效比预测误差率降低了18.18-61.70%,最终能够在两个园区上每月节省252 MWh的电量,与当前建筑中冷水机的运行方式相比节省了36.75%以上的能源。
华为云边缘云创新Lab:愿景是探索端边云协同关键技术,构建无所不在的、极致体验的智能边缘云。联合工业伙伴和学术机构,共同致力于研究边缘云创新技术、孵化边缘云创新应用、构建边缘云繁荣生态。研究方向包括大规模智能边缘云平台、边云协同AI、端边云协同渲染与视频加速。目前已孵化上线华为边缘计算平台IEF,并贡献首个基于Kubernetes的云原生边缘计算平台KubeEdge,获尖峰开源技术创新奖、最佳智能边缘计算技术创新平台等多项奖项;孵化的业内首个边云协同增量学习工作流即将上线华为云HiLens服务、IEF服务;学术上近2年已发表7篇边云协同AI、云原生边缘计算相关顶会论文,获多项最佳论文和优秀论文奖项。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
 微信扫一扫
微信扫一扫